Optimizing HTTP: Keep-alive and Pipelining
 The last major update to the HTTP spec dates back to 1999, at which time RFC 2616 standardized HTTP 1.1 and introduced the much needed keep-alive and pipelining support. Whereas HTTP 1.0 required strict "single request per connection" model, HTTP 1.1 reversed this behavior: by default, an HTTP 1.1 client and server keep the connection open, unless the client indicates otherwise (via Connection: close header).
The last major update to the HTTP spec dates back to 1999, at which time RFC 2616 standardized HTTP 1.1 and introduced the much needed keep-alive and pipelining support. Whereas HTTP 1.0 required strict "single request per connection" model, HTTP 1.1 reversed this behavior: by default, an HTTP 1.1 client and server keep the connection open, unless the client indicates otherwise (via Connection: close header).
Why bother? Setting up a TCP connection is very expensive! Even in an optimized case, a full one-way route between the client and server can take 10-50ms. Now multiply that three times to complete the TCP handshake, and we're already looking at a 150ms ceiling! Keep-alive allows us to reuse the same connection between different requests and amortize this cost.
The only problem is, more often than not, as developers we tend to forget this. Take a look at your own code, how often do you reuse an HTTP connection? Same problem is found in most API wrappers, and even standard HTTP libraries of most languages, which disable keepalive by default.
HTTP Pipelining
The good news is, keep-alive is supported by all modern browsers and mostly works out of the box. Unfortunately, support for pipelining is in a much worse off shape: no browsers support it officially, and few developers ever think about it. Which is unfortunate, because it can yield significant performance benefits!
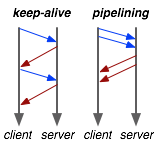 While keep-alive helps us amortize the cost of creating a TCP connection, pipelining allows us to break the strict "send a request, wait for response" model. Instead, we can dispatch multiple requests, in parallel, over the same connection, without waiting for a response in serial fashion. This may seem like a minor optimization at first, but let's consider the following scenario: request 1 and request 2 are pipelined, request 1 takes 1.5s to render on the server, whereas request 2 takes 1s. What is the total runtime?
While keep-alive helps us amortize the cost of creating a TCP connection, pipelining allows us to break the strict "send a request, wait for response" model. Instead, we can dispatch multiple requests, in parallel, over the same connection, without waiting for a response in serial fashion. This may seem like a minor optimization at first, but let's consider the following scenario: request 1 and request 2 are pipelined, request 1 takes 1.5s to render on the server, whereas request 2 takes 1s. What is the total runtime?
Of course, the answer depends on the amount of data sent back, but the lower bound is actually 1.5s! Because the requests are pipelined, both request 1 and request 2 can be processed by the server in parallel. Hence, request 2 completes before request 1, but is sent immediately after request 1 is complete. Fewer connections, faster response times - makes you wonder why nobody advertises that their API supports HTTP pipelining?
HTTP Keep-alive & Pipelining in Ruby
Unfortunately, many standard HTTP libraries revert to HTTP 1.0: one connection, one request. Ruby's own net/http uses a little known behavior where by default an "Connection: close" header is appended to each request, except when you're using the block form:
require 'net/http'
start = Time.now
Net::HTTP.start('127.0.0.1', 9000) do |http|
r1 = http.get "/?delay=1.5"
r2 = http.get "/?delay=1.0"
p Time.now - start # => 2.5 - doh! keepalive, but no pipelining
endWith the example above we get the benefits of HTTP keep-alive, but unfortunately net/http offers no support for pipelining. To enable that, you'll have to use a net-http-pipeline, which is a standalone library:
require 'net/http/pipeline'
start = Time.now
Net::HTTP.start 'localhost', 9000 do |http|
http.pipelining = true
reqs = []
reqs << Net::HTTP::Get.new('/?delay=1.5')
reqs << Net::HTTP::Get.new('/?delay=1.0')
http.pipeline reqs do |res|
puts res.code
puts res.body[0..60].inspect
end
p Time.now - start # => 1.5 - keep-alive + pipelining!
endEM-HTTP & Goliath: Keep-alive + Pipelining
While pipelining is disabled in most browsers, due to many issues related to proxies and caches, it is nonetheless a useful optimization for your own, or for talking to your partner API's. The good news is, Apache, Nginx, HAproxy and others support it, but the problem is that most app servers, even the ones which claim to be "HTTP 1.1", usually don't.
True keep-alive and pipelining support is one of the reasons we built both em-http-request and Goliath for our stack at PostRank. A simple example in action:
require 'goliath'
class Echo < Goliath::API
use Goliath::Rack::Params
use Goliath::Rack::Validation::RequiredParam, {:key => 'delay'}
def response(env)
EM::Synchrony.sleep params['delay']
[200, {}, params['delay']]
end
endrequire 'em-http-request'
EM.run do
conn = EM::HttpRequest.new('http://localhost:9000/')
start = Time.now
r1 = conn.get :query => {delay: 1.5}, :keepalive => true
r2 = conn.get :query => {delay: 1.0}
r2.callback do
p Time.now - start # => 1.5 - keep-alive + pipelining
EM.stop
end
endTotal runtime is, you guessed it, 1.5s. If your public or private API's are built on top of HTTP, then keep-alive and pipelining are features you should be leveraging wherever you can.
Optimizing HTTP: Interrogate your code!
While we love to spend time optimizing our algorithms, or making the databases faster, we often forget the basics: setting up TCP connections is expensive, and pipeling can lead to big wins. Do use reuse HTTP connections in your code? Does your app server support pipelining? The answers are usually "no, and I'm not sure", which is something we need to change!
 Ilya Grigorik is a web ecosystem engineer, author of High Performance Browser Networking (O'Reilly), and Principal Engineer at Shopify — follow on Twitter.
Ilya Grigorik is a web ecosystem engineer, author of High Performance Browser Networking (O'Reilly), and Principal Engineer at Shopify — follow on Twitter.