Mneme: Scalable Duplicate Filtering Service
 Detecting and dealing with duplicates is a common problem: sometimes we want to avoid performing an operation based on this knowledge, and at other times, like in a case of a database, we want may want to only permit an operation based on a hit in the filter (ex: skip disk access on a cache miss). How do we build a system to solve the problem? The solution will depend on the amount of data, frequency of access, maintenance overhead, language, and so on. There are many ways to solve this puzzle.
Detecting and dealing with duplicates is a common problem: sometimes we want to avoid performing an operation based on this knowledge, and at other times, like in a case of a database, we want may want to only permit an operation based on a hit in the filter (ex: skip disk access on a cache miss). How do we build a system to solve the problem? The solution will depend on the amount of data, frequency of access, maintenance overhead, language, and so on. There are many ways to solve this puzzle.
In fact, that is the problem - they are too many ways. Having reimplemented at least half a dozen solutions in various languages and with various characteristics at PostRank, we arrived at the following requirements: we want a system that is able to scale to hundreds of millions of keys, we want it to be as space efficient as possible, have minimal maintenance, provide low latency access, and impose no language barriers. The tradeoff: we will accept a certain (customizable) degree of error, and we will not persist the keys forever.
Mneme: Duplicate filter & detection
Mneme is an HTTP web-service for recording and identifying previously seen records - aka, duplicate detection. To achieve the above requirements, it is implemented via a collection of bloomfilters. Each bloomfilter is responsible for efficiently storing the set membership information about a particular key for a defined period of time. Need to filter your keys for the trailing 24 hours? Mneme can create and automatically rotate 24 hourly filters on your behalf - no maintenance required.
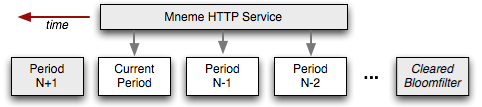
By using a bloomfilter as the underlying datastore we can efficiently test for set membership while minimizing the amount of memory (review the background on bloomfilters here). Instead of storing the actual keys we can instead define the exact number of bits we will store per key by trading off against an acceptable error rate - the fewer bits, the higher the probability of a false positive.
Mneme: Goliath, Redis, HTTP and JSON
To meet all of our original criteria, Mneme is powered by a few components under the hood: Goliath web server, Redis for in-memory storage of the filters, and HTTP + JSON. The bloomfilter is stored inside of a bitstring in Redis, which allows us to easily query and share the same dataset between multiple services, and Goliath provides the high-performance HTTP frontend which abstracts all of the filter logic behind simple GET and POST operations:
$ curl "http://mneme:9000?key=abcd"
# {"found":[],"missing":["abcd"]}
# -d creates a POST request with key=abcd, aka insert into filter
$ curl "http://mneme:9000?key=abcd" -d' '
$ curl "http://mneme:9000?key=abcd"
#{"found":["abcd"],"missing":[]}That's it. You can query for a single or multiple keys via a simple GET operation, and you can insert keys into the filter via a POST operation. The rest is taken care of by Mneme.
Configuring & Launching Mneme
Launching the service is as simple as installing the gem and starting up Redis:
$ redis-server
$ gem install mneme
$ mneme -p 9000 -sv -c config.rb # run with -h to see all optionsOnce the gem is installed you will have a mneme executable which will start the Goliath web server. To launch the service, we just need to provide a configuration file to specify the length of time to store the data for, the granularity and the error rate:
config['namespace'] = 'default' # namespace for your app (if you're sharing a redis instance)
config['periods'] = 3 # number of periods to store data for
config['length'] = 60 # length of a period in seconds (length = 60, periods = 3.. 180s worth of data)
config['size'] = 1000 # expected number of keys per period
config['bits'] = 10 # number of bits allocated per key
config['hashes'] = 7 # number of times each key will be hashed
config['seed'] = 30 # seed value for the hash functionmneme.git - HTTP web-service for recording and identifying previously seen records
Once again, to figure out your size, bits, and hashes, revisit the math behind bloomfilters. With the config file in place, you can launch the service and you are ready to go.
Mneme Performance & Memory Requirements
The cost of storing a new key in Mneme is O(num hashes), or O(1), since we only need to update the most recent filter. Similarly, retrieving a key is in the worst case O(num filters * num hashes), or once again, O(1). In both cases the performance is not dependent on number of keys, but rather on the time period and the error rate!
What about the memory footprint? Each filter is stored inside of a Redis bitstring, and GETBIT/SETBIT operations are used under the hood to perform the required operations. Redis does add some overhead to our bitstring, but a quick test shows that for a 1.0% error rate and 1M items, we need just about 2.5mb of memory! For more numbers, check the Mneme readme.
Simple to deploy, minimal maintenance, high performance and no language barriers. Give it a try, and hopefully it will help you avoid having to reimplement yet another duplicate filter solution!
 Ilya Grigorik is a web ecosystem engineer, author of High Performance Browser Networking (O'Reilly), and Principal Engineer at Shopify — follow on Twitter.
Ilya Grigorik is a web ecosystem engineer, author of High Performance Browser Networking (O'Reilly), and Principal Engineer at Shopify — follow on Twitter.